GraphQL.
개념이 방대하서 어떻게 정리를 해야 하나 고민을 했다.
아이에 안 쓸 수도 없고.
막막함을 없애기 위해
일단 무작정 쓰고 본다.
그래야지 조금씩 정리가 될 것 같다. 해당 글은 front-end기준으로 작성하였다.
스키마 작성, API 제작은 이후에 알아보도록 하자.
GraphQL
우선 GraphQL을 알려면
ResT 방식도 알아야 한다.
기존에 사용하던 REST 방식이 불편하여 나온 것이 바로 GraphQL이기 때문이다.
기존 Rest는 필요한 데이터만 받아오는 것이 힘들었다.
그리고 iOS와 Android에서 필요한 것이 달라 각각의 API를 구현하는 것이 힘들었다.
이런 큰 이유로 GraphQL이 나오게 됐다.
GraphQL Query 언어의 장점
내가 원하는 것만 가져오기
GraphQL은 서버에 데이터 요청을 할 때 Query(질의)를 할 수 있다.
같은 요청이라도 내가 어떤 것만 원하는지에 따라 다르게 데이터를 받을 수 있다는 것이다.
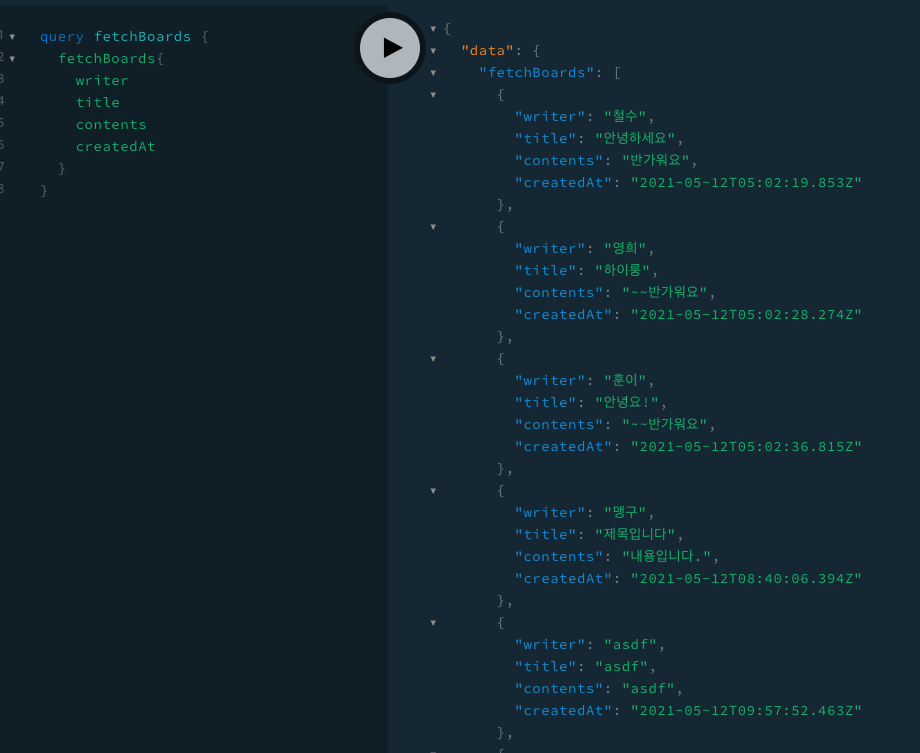
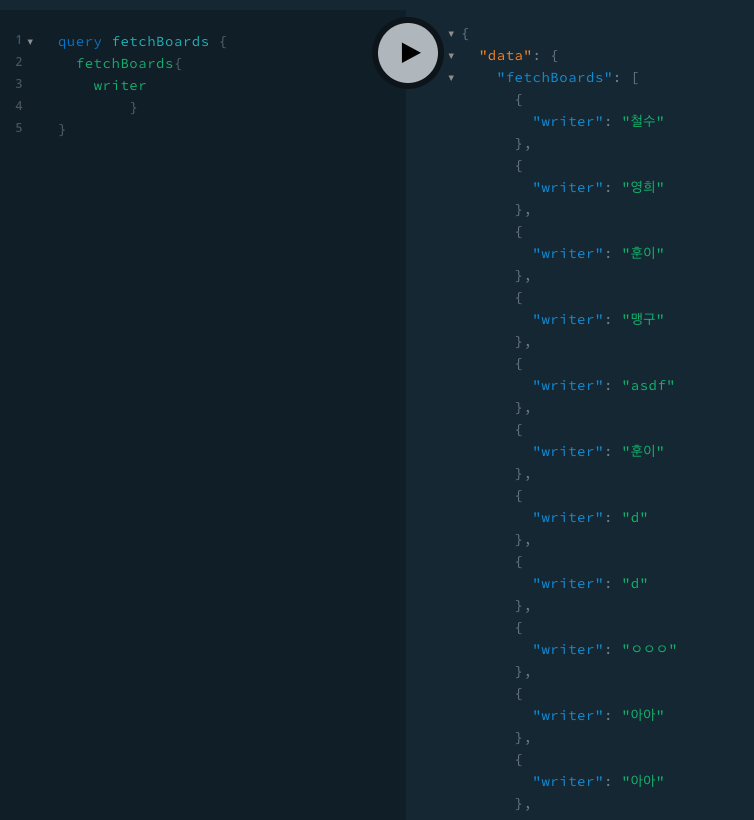
위에 playground에서 테스트한 결과를 살펴보자.
같은 fetchBoards(게시글 전체 받아오기) 기능이다.
하지만 내용 안에 내가 writer만 받고 싶은지, 혹은 title, contents 등 다른 정보도 받고 싶은지에 따라
내가 받을 수 있는 결과의 data가 달라지게 된다.
이를 통해 데이터가 가벼워지고, front-end, Back-end모두 편리해질 수 있다.
하지만 Rest 같은 경우 각각의 API를 모두 만들어야 하거나,
front-end가 모든 데이터를 받고 따로 데이터를 저장해야 하는 불편함이 있다.
그렇게 되면 데이터도 무거워지게 된다.
나의 요청에 따라 달라지기 때문에 Query를 반영한다고 표현한다.
GraphQL의 다른 장점
위에서 살펴본 장점은
EndPoint를 줄임으로써 하나의 API를 통해 여러 기능을 할 수 있다는 것이다.
또한 데이터를 원하는 것만 받아 무게가 가벼워질 수 있다.
그 외에도 iOS, Android에 동일한 API를 적용할 수 있다.
하지만 안타깝게도 작성자가 iOS와 Android를 따로따로 API를 만들거나 사용한 경험이 없다.
그래서 예시는 모르겠다.
그리고 Apollo와 같이 사용할 때 전역상태 관리가 편한다.
기존 Redux는 action이나 패치 등을 사용해야 했지만..
이 부분은 나중에 코드로 한 번 더 작성하려고 한다!
GraphQL의 단점
HTTP 캐싱이 불편함
우선 HTTP 캐싱이 무엇인지 알아보자.
웹 사이트에서 데이터를 자동 보관하는 것이 캐시이다.
캐시를 활용하게 된다면 중복된 데이터를 다시 받아오지 않고, 보관함에서 가져오게 된다.
이를 통해 전송량을 줄이고, 더 빠르게 응답할 수 있다.
REST같은 경우는 HTTP가 주는 캐싱기능을 그대로 적용할 수 있다. 하지만 graphQL 같은 경우 apollo의 도움을 받아야 한다.
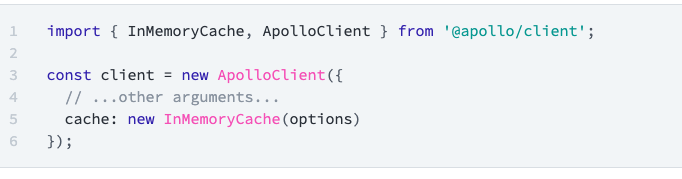
해당 사진은 아폴로 공식 사이트에서 가져왔다.
위에 처럼 InMemoryCache를 적용시켜야 한다.
아직도 graphQL의 내용이 엄청 많다.
다음에는 조금 더 심화 과정을 쓸 수 있기를 바란다.